Ich habe gerade mal geschaut... es war im Mai, wo ich den letzten Beitrag zum Thema Plattenverwaltung 4.0 geschrieben hatte. Es folgte eine lange Phase der Orientierungslosigkeit - wie sollte jetzt meine Oberfläche aussehen? Ich hatte vor Jahren auf Arbeit ein kleines Programm geschrieben, dass einige überschaubare Funktionen erfüllen sollte, die über Tab-Reiter auswählbar waren. So ähnlich stellte ich mir meine neue Oberfläche vor und fing an. Zuerst fing ich mit den Basics an: Die Tab-Reiter einzeln anwählbar machen und dementsprechend den Content auf der Hauptoberfläche (der nur simuliert war) umschalten. Dann spielte ich noch etwas mit Farben herum und gelangte dann zu einem ersten Entwurf, der mir zusagte.
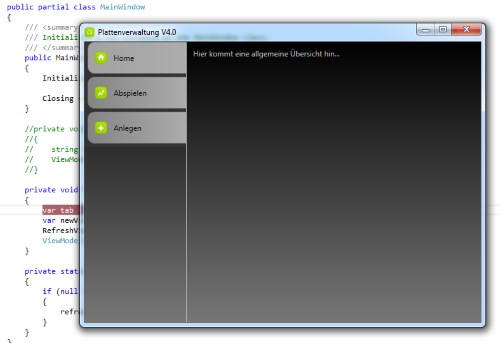
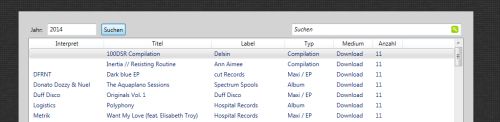
Als ich anfing die einzelnen Aspekte der Oberfläche (Home, Anlegen, Abspielen) mit Leben zu füllen, kollidierte ich immer wieder mit meinen Farbeinstellungen. Also flog alles was farbig war, raus und schon arbeitete ich mit einer ziemlich nackt aussehenden Windowsoberfläche weiter. Als erstes ging es mit dem Abspielen los, da diese Funktionalität die einfachste war. Ich hatte schon mal mit einem Such-Control herum-experimentiert und band es ein. Bei meiner alten Plattenverwaltung hat es mich immer wahnsinnig genervt, dass ich ewig herumscrollen musste, um eine Platte zu finden. Es versprach alles einfacher zu werden. Die ersten Testläufe gegen meine simulierte Datenbank funktionierten perfekt. Also konnte ich mich dem nächsten Punkt zuwenden...
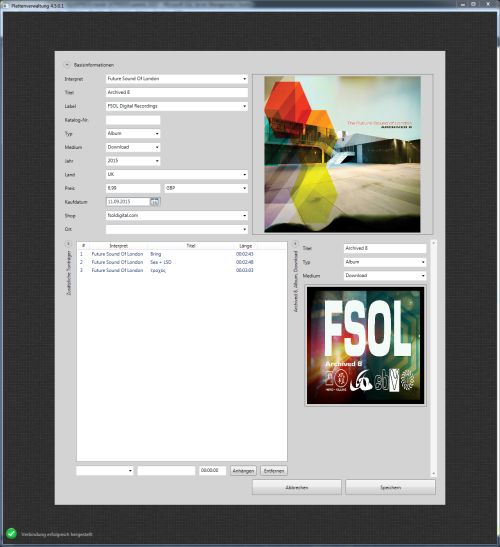
 Das Anlegen war der nächste Punkt, den ich auf dem Plan hatte. Ich klebte erstmal alle Controls auf die Oberfläche, ordnete sie ein bisschen, sorgte für ein anständiges Databinding (Für Laien: Die Daten und die Oberfläche miteinander verknüpfen) und dann gingen die ersten Tests los. Hier klappte was mit der Aktualisierung nicht, da kollidierte der Datentyp mit der Darstellung. Kleine Problemchen, die ich alle mit einer Suchanfrage lösen konnte. Hin und wieder schon ich die Controls zurecht, bis ich so halbwegs zufrieden war. Es konnte der letzte und entscheidende Schritt folgen: Ersetzen der Dummy-Daten durch den richtigen Datenbankzugriff. Hier tat ich mich anfänglich schwer, aber als ich einmal den Rhythmus raus hatte, war auch die Datenbank zügig angebunden.
Das Anlegen war der nächste Punkt, den ich auf dem Plan hatte. Ich klebte erstmal alle Controls auf die Oberfläche, ordnete sie ein bisschen, sorgte für ein anständiges Databinding (Für Laien: Die Daten und die Oberfläche miteinander verknüpfen) und dann gingen die ersten Tests los. Hier klappte was mit der Aktualisierung nicht, da kollidierte der Datentyp mit der Darstellung. Kleine Problemchen, die ich alle mit einer Suchanfrage lösen konnte. Hin und wieder schon ich die Controls zurecht, bis ich so halbwegs zufrieden war. Es konnte der letzte und entscheidende Schritt folgen: Ersetzen der Dummy-Daten durch den richtigen Datenbankzugriff. Hier tat ich mich anfänglich schwer, aber als ich einmal den Rhythmus raus hatte, war auch die Datenbank zügig angebunden.
Nachdem ich begann die einzelnen Programmpunkte mal testhalber anzuwählen, wurden mir klar, dass mich das Design kolossal nervte. Das mit den Tab-Reitern war zu umständlich und verbrauchte ständig Platz. Lieber eine einfach Startoberfläche und dann von dort aus die einzelnen Programmpunkte anwählen. Gesagt, getan... Das Schicke daran war, dass ich mich nur um das Startmenü kümmern musste, alle anderen Programmteile schalteten schon von allein auf den vorherigen Punkt zurück.
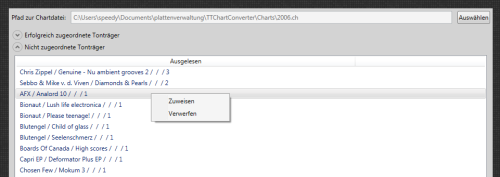
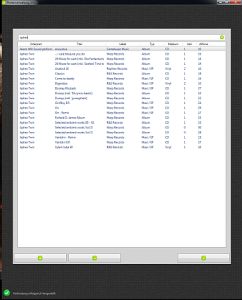 Der Test konnte weiter gehen - einzelne Platten als abgespielt markieren. Die Datenbankanbindung arbeitete fast perfekt - einmal wurden alle Platten geladen und dann wurde entsprechend dem Filter immer nur ein- und ausgeblendet. Markierte Platten wurden in eine extra Liste geschoben, die zum Schluss gespeichert wurde. Nur der Filter brachte mich zur Verzweiflung. Einmal gefiltert, wurde die Liste nie neu sortiert, sondern die vorher ausgeblendeten Platten wurde einfach wieder unten an die Liste angehängt. Also - neu sortieren nach jedem Filtern. Hatte ich mich im Filter vertippt und die Liste war dadurch leer, konnte ich den Suchbegriff entfernen oder was anderes Suchen - die Liste blieb leer. Mh, ein Aktualisierungsproblem, auch gelöst. Jetzt endlich konnte ich den Punkt ordentlich ausprobieren. Dumm war nur, dass mir die Fehler erst auffielen, als ich die Daten schon in die Datenbank geschrieben hatte. Äußerte sich dadurch, dass auch nicht gespielte Platten in der Liste befanden. Nachdem vermeintlich alles erledigt war, markierte ich, verließ dem Programmpunkt, wählte ich in wieder an, markierte weiter und hoppla... da waren noch die alten Elemente in der Liste. Bloß gut, dass ich das rechtzeitig gemerkt habe.
Der Test konnte weiter gehen - einzelne Platten als abgespielt markieren. Die Datenbankanbindung arbeitete fast perfekt - einmal wurden alle Platten geladen und dann wurde entsprechend dem Filter immer nur ein- und ausgeblendet. Markierte Platten wurden in eine extra Liste geschoben, die zum Schluss gespeichert wurde. Nur der Filter brachte mich zur Verzweiflung. Einmal gefiltert, wurde die Liste nie neu sortiert, sondern die vorher ausgeblendeten Platten wurde einfach wieder unten an die Liste angehängt. Also - neu sortieren nach jedem Filtern. Hatte ich mich im Filter vertippt und die Liste war dadurch leer, konnte ich den Suchbegriff entfernen oder was anderes Suchen - die Liste blieb leer. Mh, ein Aktualisierungsproblem, auch gelöst. Jetzt endlich konnte ich den Punkt ordentlich ausprobieren. Dumm war nur, dass mir die Fehler erst auffielen, als ich die Daten schon in die Datenbank geschrieben hatte. Äußerte sich dadurch, dass auch nicht gespielte Platten in der Liste befanden. Nachdem vermeintlich alles erledigt war, markierte ich, verließ dem Programmpunkt, wählte ich in wieder an, markierte weiter und hoppla... da waren noch die alten Elemente in der Liste. Bloß gut, dass ich das rechtzeitig gemerkt habe.
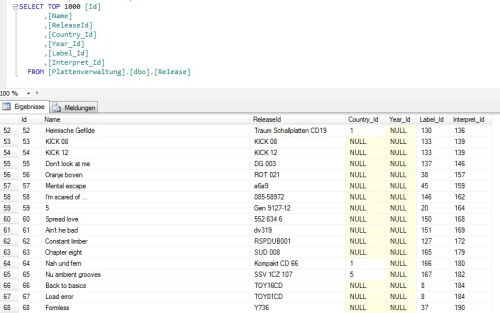
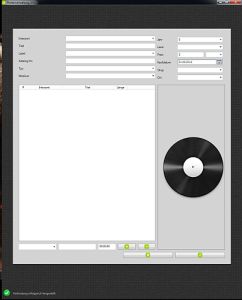 Anlegen entpuppte sich größtenteils als Fleißarbeit. Natürlich mussten jede Menge Daten geschrieben und gelesen werden, aber das ging sehr zügig von der Hand. Meine größte Sorge war ob das Framework die Verknüpfungen zwischen den Objekten gut hingekommt. Aber auch das lief sauber durch. Einzig die Persistierung (das dauerhafte Speichen der Daten) stellte sich quer, denn ich habe eine Verknüpfung zwischen der Platte und dem Interpreten bzw. dem einzelnen Titel und dem Interpreten. Das bescherte mir bei einer Single mit 2 Titeln drei mal den gleichen Interpreten als neue Datensätze. Als ich damit fertig war, konnte ich in den Praxistest gehen. Seither läuft das Programm in der Betaphase, d.h. ich starte es in der Entwicklungsumgebung und schaue immer mal auf die Daten, die so hin- und herhuschen.
Anlegen entpuppte sich größtenteils als Fleißarbeit. Natürlich mussten jede Menge Daten geschrieben und gelesen werden, aber das ging sehr zügig von der Hand. Meine größte Sorge war ob das Framework die Verknüpfungen zwischen den Objekten gut hingekommt. Aber auch das lief sauber durch. Einzig die Persistierung (das dauerhafte Speichen der Daten) stellte sich quer, denn ich habe eine Verknüpfung zwischen der Platte und dem Interpreten bzw. dem einzelnen Titel und dem Interpreten. Das bescherte mir bei einer Single mit 2 Titeln drei mal den gleichen Interpreten als neue Datensätze. Als ich damit fertig war, konnte ich in den Praxistest gehen. Seither läuft das Programm in der Betaphase, d.h. ich starte es in der Entwicklungsumgebung und schaue immer mal auf die Daten, die so hin- und herhuschen.

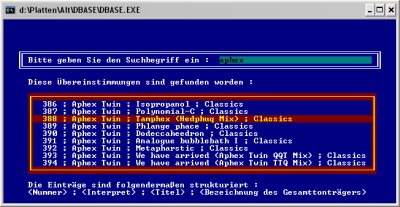 Nachdem sich
Nachdem sich 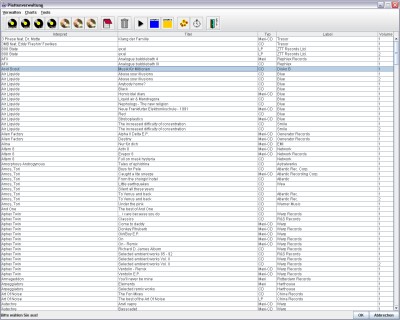 Trotzdem fehlten immer wieder entscheidende Funktionen zur Auswertung und Erfassung. Außerdem war das DOS-Fenster dermaßen veraltet, dass ich mich 2000 nach einem Semester Java-Programmierung an die Umstellung auf eine Version in Java machte. Ich exportierte die Daten aus der Tabelle, schrieb eine Konvertierungsroutine, die mir meine Daten in mein neues Format umsetzte. Nach einiger Zeit war dann die V2.0 fertig und ich verbesserte und erweiterte das Programm noch bis zur V2.4 und immer mehr stolperte ich über Unzulänglichkeiten in meiner Programmarchitektur. Da sich meine Kenntnisse nur auf das AWT bezogen, ich aber das Programm komplett mit Swing programmiert hatte, waren mir Begriffe, wie das
Trotzdem fehlten immer wieder entscheidende Funktionen zur Auswertung und Erfassung. Außerdem war das DOS-Fenster dermaßen veraltet, dass ich mich 2000 nach einem Semester Java-Programmierung an die Umstellung auf eine Version in Java machte. Ich exportierte die Daten aus der Tabelle, schrieb eine Konvertierungsroutine, die mir meine Daten in mein neues Format umsetzte. Nach einiger Zeit war dann die V2.0 fertig und ich verbesserte und erweiterte das Programm noch bis zur V2.4 und immer mehr stolperte ich über Unzulänglichkeiten in meiner Programmarchitektur. Da sich meine Kenntnisse nur auf das AWT bezogen, ich aber das Programm komplett mit Swing programmiert hatte, waren mir Begriffe, wie das 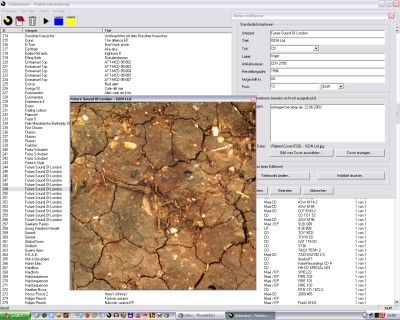 Also warf ich alles über den Haufen und begann mit einer kompletten Neuprogrammierung, diesmal mit den frisch erworbenen
Also warf ich alles über den Haufen und begann mit einer kompletten Neuprogrammierung, diesmal mit den frisch erworbenen