Und schon ist sie da – die nächste Folge zur Plattenverwaltung V4.0. Ich habe eigentlich die letzten Jahre darauf „verschwendet“, an meinem Datenmodell zu feilen. Werfen wir aber zuerst mal einen Blick auf das aktuelle Datenmodell, wie es in Version 3.x eingesetzt wird. Ich speichere die Daten in einer Textdatei. Dort steht pro physikalischem Tonträger eine Zeile drin, d.h. für ein Doppelalbum wären das zwei Zeilen. Dabei reihen sich folgende Daten durch Paragraphenzeichen getrennt auf:
- Interpret (bei Compilations steht hier „Verschiedene“
- Name der Platte
- Typ (Single, Maxi / EP, Maxi-CD, LP, CD, Compilation und CD-Compilation sind mögliche Werte)
- Nummer des Tonträgers (z.B. bei Doppelalben 1 von 2)
- Gesamtzahl der Tonträger
- Label
- Katalognummer
- Herstellerland
- Freitext (meistens enthalten: Ort und Datum wo ich das Ding gekauft hab)
- Pfad zum Coverbild
- Preis
- Währung
- Schalter, ob Titel vorhanden sind
- Wie oft wurde der Tonträger im aktuellen Jahr abgespielt?
- Wie oft wurde der Tonträger insgesamt abgespielt?
- Anzahl der Titel
- Jetzt folgen in Dreierpärchen: Interpret (nur bei Compilations gefüllt) / Titel / Länge des Titels
Daran war erstmal nicht viel fehlerhaft. Es gab nur einen tückischen Fehler: Wenn der Schalter, ob Titel vorhanden sind auf 0 stand, wurde der Tonträger nicht in den Charts berücksichtigt. Ansonsten habe ich versucht, so viele Ungereimtheiten zu entfernen, wie es nur irgend ging.

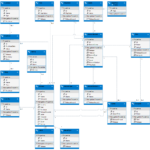
Schauen wir und das neue Datenmodell mal von unten nach oben an. Es beginnt mit dem Label, dass die Platten veröffentlicht. Früher war das mehr oder weniger Freitext, jetzt ist es normalisiert und ich habe die Chance zu sehen, welche Releases ich von welchem Label habe. Daran schließt sich der Release an. Unter Release verstehe ich die Zusammenfassung aller Tonträger die zu einer Veröffentlichung gehören, also z.B. das jetzt schon oft zitierte Doppelalbum. Ein Blick nach links zeigt und das Land, wo der Release herkommt. Folgt man in die Mitte des Bildes hängt dort Repräsentation der physischen Platte. Jede Platte kann ein Cover haben. Jetzt kommt eine Neuerung gegenüber dem alten Modell – ich habe gelernt, dass z.B. eine Maxi-CD eine Zusammenfassung von Typ und Medium war. In Zeiten des Downloads lade ich mir eine Maxi runter, die aber keine Schallplatte ist. Demzufolge musste eine Trennung her. Der Typ wäre jetzt „Maxi / EP“ und das Medium „CD“ oder „Vinyl“ oder „Download“. Für mich eigentlich eine der Verbesserungen in diesem Datenmodell.
Ganz rechts befinden sich die einzelnen Titel, die Interpreten zugeordnet sind, wie auch der Release einem Interpreten zugeordnet werden kann. Links oben habe ich jetzt Teile eingeführt, die ich zwar schon so gepflegt habe, aber nie richtig zugeordnet habe – den Kauf der Platte nach Ort, Wert und Währung. Es gibt dann auch noch das Jahr der Veröffentlichung separat – eine Verteilung der Platten nach Jahren lässt grüßen. Und zu guter letzt noch die Charts, die in Alltime-Charts und Jahres-Charts unterteilt sind. Neu ist hier das Datum des letzten Abspielen – so finde ich richtig alte Platten wieder. Was noch neu ist, ist der Name einer einzelnen Platte. Sammelboxen haben mich dazu gezwungen, z.B. wurde von Gas seine alten Werke unter dem Titel „Nah und fern“ neu aufgelegt. Sie setzen sich zusammen aus den einzelnen Tonträgern „Königsforst“, „Gas“ usw.
Wie geht es jetzt weiter? Das Datenmodell ist da – jetzt müssen nur noch die Daten aus der Textdatei in den SQL-Server wandern, d.h. der nächste Schritt ist ein Datenkonvertierer, der die alte Datei nimmt, aufbereitet (gerade meine Einkäufe müssen von Freitext in sinnvolle Strukturen gebracht werden) und dann abspeichert. Dann kommt die unangenehme Aufgabe, dass ich die neu entstandenen Objekte bereinigen muss, d.h. „WARP“, „Warp“ und „Warp Records“ müssen zusammengefasst werden. Wird wohl so laufen, dass ich die Korrekturen in der Textdatei vornehme und dann wieder von vorn einlese.